近日,阿里云在其官方渠道宣布了一项重大突破,其最新研发的通义千问Qwen 2.5-Max超大规模MoE模型在新年之际崭露头角。该模型在多个基准测试中表现出色,据称已超越了包括DeepSeek V3在内的多个竞争对手。
具体而言,阿里云透露,Qwen2.5-Max在备受瞩目的Chatbot Arena大模型盲测中取得了令人瞩目的成绩。在这一由LMSYS Org推出的性能测试平台上,Qwen2.5-Max与DeepSeek-V3、Open AI的o1-mini以及Claude-3.5-Sonnet等模型同台竞技,最终以1332分的总成绩位列全球第七,同时摘得非推理类中国大模型的桂冠。
不仅如此,Qwen2.5-Max在数学和编程等领域的单项能力测试中更是独占鳌头,展现出了强大的专业实力。同时,在硬提示(Hard prompts)方面的测试中,该模型也获得了第二名的优异成绩。

据了解,Chatbot Arena平台以其公正、权威的测试方式而广受业界认可。该平台采用匿名方式将大模型进行两两配对,交由用户进行盲测。用户根据与模型的对话体验,对模型的能力进行投票。因此,Chatbot Arena的LLM排行榜成为了衡量大模型性能的重要标准之一,吸引了全球顶级大模型在此一决高下。
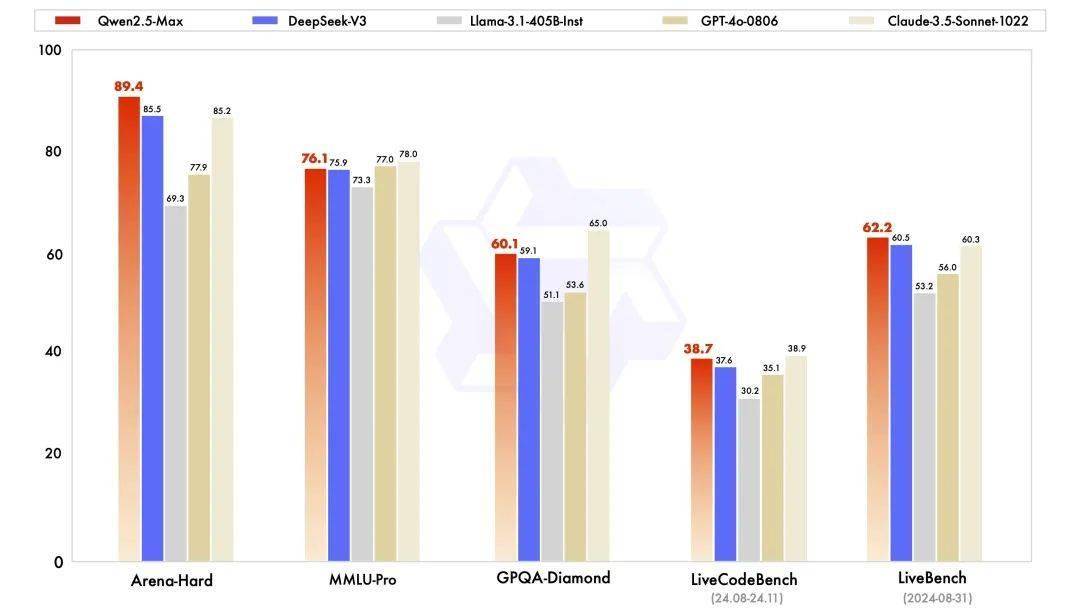
阿里云进一步指出,Qwen2.5-Max在多个主流基准测试中均表现出色。在Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond以及MMLU-Pro等测试中,该模型与Claude-3.5-Sonnet不相上下,同时几乎全面超越了GPT-4o、DeepSeek-V3以及Llama-3.1-405B等强劲对手。
此次Qwen2.5-Max的出色表现,不仅彰显了阿里云在人工智能领域的深厚积累与创新能力,也为中国大模型在全球舞台上赢得了更多关注与认可。