在近期科技界的一次重大突破中,OpenAI推出了一项名为RFT(基于强化学习的微调)的新型训练方法,该方法迅速吸引了全球的目光。RFT通过结合强化学习与监督微调技术,实现了在有限标注数据下模型性能的显著提升。紧接着,这一创新技术被百度智能云千帆ModelBuilder平台引入国内,成为首个全面支持RFT的大模型开发平台,为企业开发者开辟了一条高效、低成本的大模型开发路径。
RFT技术的核心在于其融合了强化学习(RL)与微调(Fine-tuning)的优势,打破了传统训练方式对于大量人工标注数据的依赖。通过引入一个称为Grader的模块,RFT能够自动比较模型的输出与参考答案,并生成0-1之间的量化奖励信号,以此驱动模型的优化过程。这种机制不仅提高了数据利用效率,还使模型能够自主思考,强化正确的思维路径,抑制错误的路径。
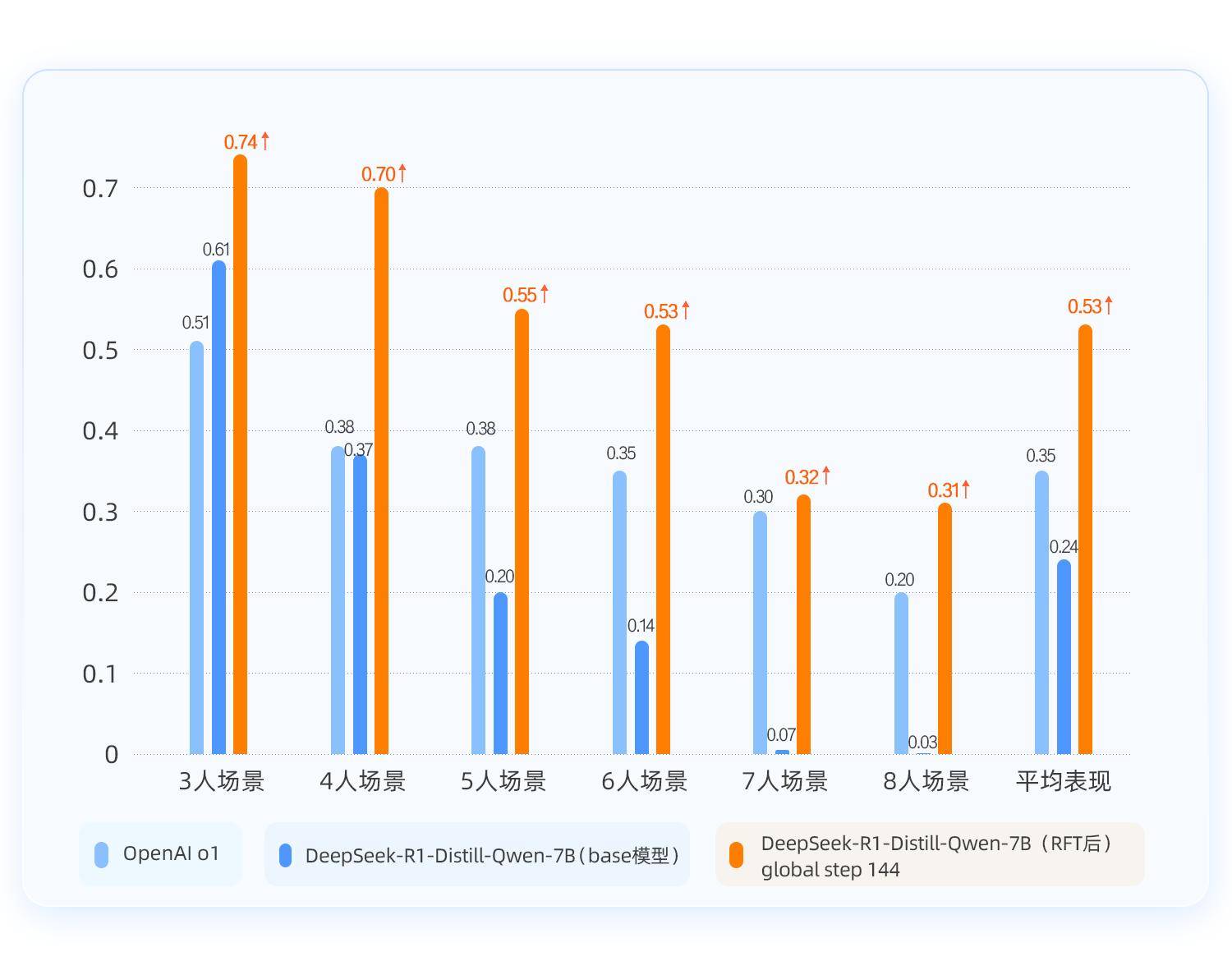
在实际应用中,RFT展现出了令人瞩目的效果。在复杂场景下,仅需4500条训练数据,RFT就能使模型达到令人满意的性能水平。在涉及逻辑推理的任务中,RFT训练后的模型在准确率上有了显著提升,甚至超越了OpenAI的o1模型。这一成就不仅体现在平均准确率的提高上,更在于模型在面对不同难度任务时的稳定表现。
百度智能云千帆ModelBuilder平台上的RFT训练流程简洁高效。用户只需按照平台指引,创建RFT训练任务,选择基础模型,并配置奖励规则。随后,准备包含问题和参考答案的训练数据,即可开始训练过程。训练完成后,用户可以在平台上一键部署模型,并通过自动评估任务快速获得模型效果反馈。
以实际案例为例,在“好人/坏人”推理场景中,RFT训练后的模型在3-8人复杂度递增的任务中,平均准确率相比基础模型提升了29%。这一提升不仅体现在准确率的数字上,更在于模型在推理过程中的清晰度和逻辑性。在RFT训练前,基础模型的输出答案和思考过程往往存在明显错误,尤其是在任务难度增加时,模型甚至会出现语言混乱的情况。而经过RFT训练后,模型的输出答案准确,思考过程也更加条理清晰。

RFT技术还展现出了更高的训练天花板。在复杂问题场景下,RFT训练后的模型相比传统监督微调方法(SFT)在准确率上有了更显著的提升。这表明RFT在处理复杂任务时具有更强的适应性和优化能力。
百度智能云千帆ModelBuilder平台的RFT训练流程不仅简化了大模型开发的复杂度,还降低了生成式AI应用落地的门槛。通过RFT技术,企业开发者能够更高效地利用有限的数据资源,训练出性能卓越的模型,为各行业的智能化转型提供有力支持。