近期,生物科技领域迎来了一项重大突破。随着生物测序技术的飞速发展,全球天然基因库中已积累了数十亿级别的序列数据,其中隐藏着无数具有极高价值的功能基因。然而,遗憾的是,目前仅有少数几个“明星基因”得到了深入的研究和开发,绝大多数基因仍然处于未被发掘的状态。
为了改变这一现状,中国科学院深圳先进技术研究院定量合成生物学全国重点实验室的合成生物学研究所娄春波团队,携手北京大学定量生物学中心的钱珑团队,在国际权威学术期刊 Science Advances 上发表了一项开创性研究。他们成功开发出了全球首个专为合成生物学元件挖掘和生物制造应用设计的大语言模型——“SYMPLEX”。

SYMPLEX 模型通过结合领域大语言模型的训练、合成生物学专家知识的对齐以及大规模生物信息分析,实现了从海量生物学文献中自动化挖掘功能基因元件,并精准评估这些元件在工程化应用中的潜力。这一突破性的进展,展示了大型语言模型在生物制造领域的巨大应用潜力。
研究团队将 SYMPLEX 应用于挖掘 mRNA 疫苗生物制造中的关键酶——加帽酶。通过这一模型,他们成功发现了多种高性能的新型加帽酶。经过第三方公司的实验验证,这些新型加帽酶的催化效率远超国际知名生物科技公司 New England Biolabs(NEB)的商业化加帽酶,催化效率提高了两倍以上,从而显著提升了 mRNA 疫苗的生产效率和成本效益。
研究团队的创新之处在于,他们将大型语言模型(LLM)与结构化的生物知识库进行了深度融合,开发出 SYMPLEX 智能基因挖掘平台。这一平台能够自动化阅读和理解海量的生物学文献,从基因、功能和知识三个层面对文献内容进行提取和分析。通过与专家数据库进行概念对齐和交互,以及基于先进生物信息技术的统计模式生成,SYMPLEX 能够提供具有完整证据链的高质量候选基因集合。
SYMPLEX 不仅有效避免了大型语言模型可能出现的幻觉问题,还能够自动生成与基因功能相关的细粒度知识树。这一功能为科学家提供了宝贵的工具,引导他们深入探索广泛的生物机制和分子过程。
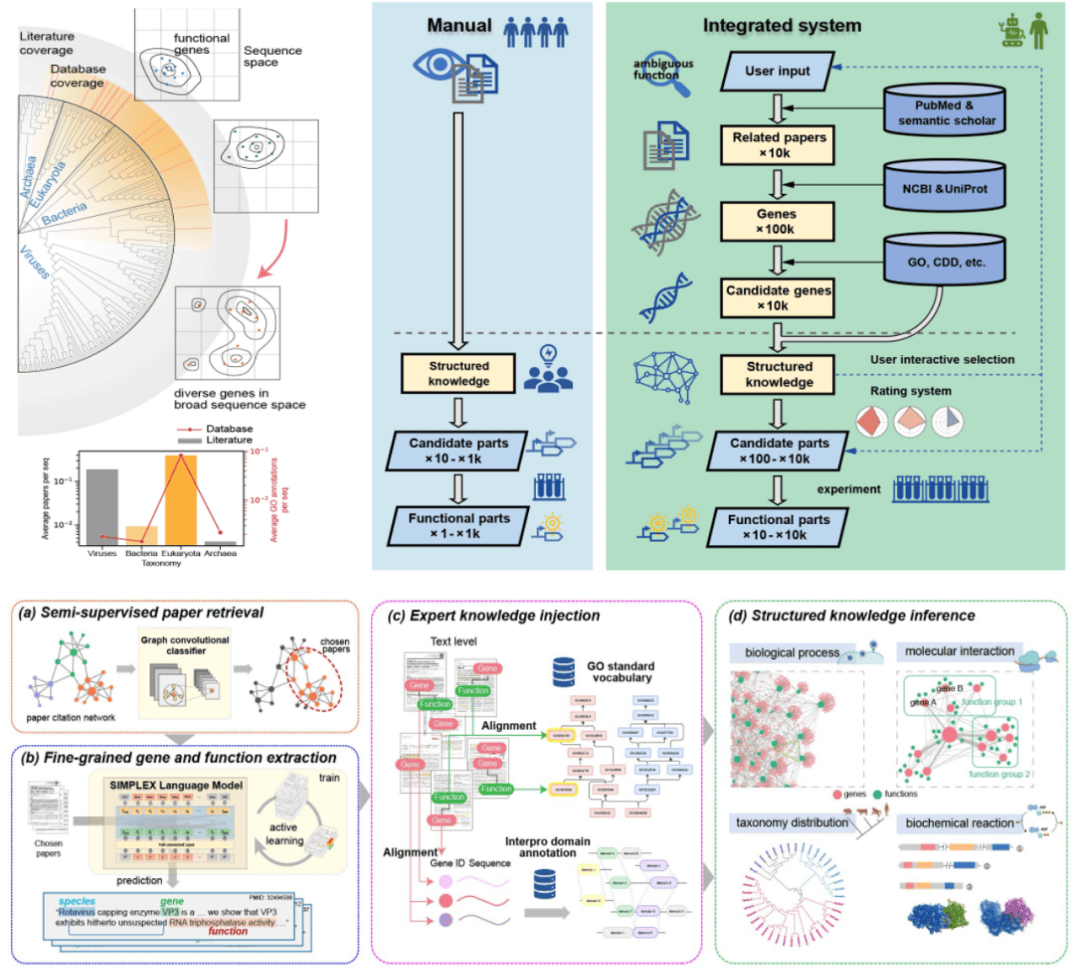
与传统基因挖掘流程相比,SYMPLEX 大模型在挖掘基因的深度、数量和多样性方面都表现出显著的优势。其挖掘的基因多样性甚至超越了现有蛋白质功能预测模型的边界。这一突破性的进展,无疑为生物科技领域带来了新的希望和机遇。
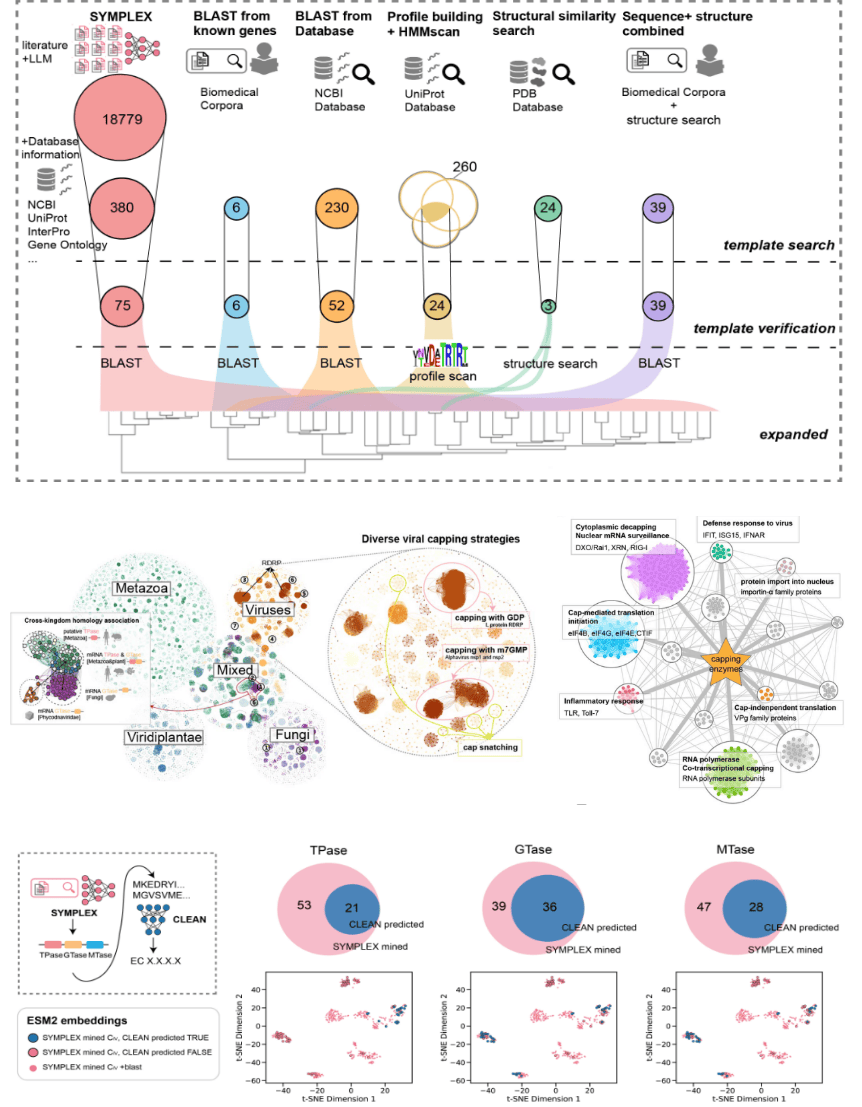
目前,SYMPLEX 在线交互式平台已经正式上线,供研究人员使用。该平台采用模块化设计,提供了三个核心功能:文献智能提取引擎 PubEngine,支持高通量的文献智能检索分析与可视化交互;基因功能标注系统 GeneTagger,实现从分子机制到生物过程的细粒度自动化基因与功能提取;以及标准化知识中枢 GeneNorm,实现与专家知识库的概念对齐与标准化,支持知识树构建和功能模式识别。