近日,字节跳动旗下的豆包大模型团队揭晓了其最新思考模型Seed-Thinking-v1.5的技术细节,并宣布该模型将于4月17日通过火山引擎开放接口供用户体验。这一消息标志着字节跳动在自然语言处理领域迈出了重要一步。
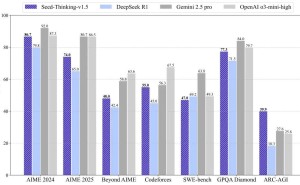
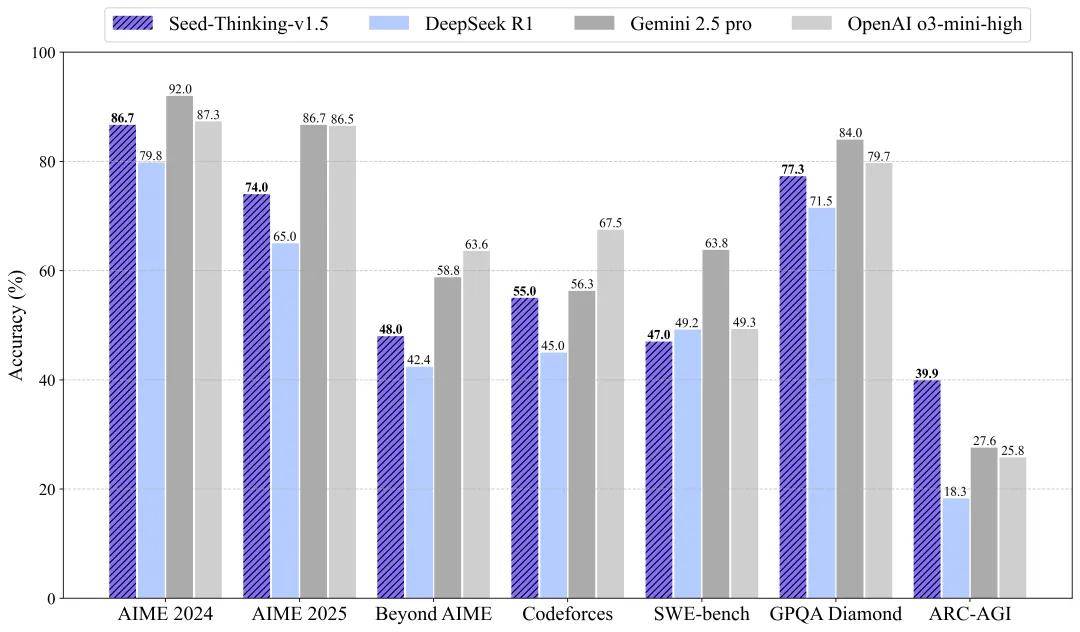
Seed-Thinking-v1.5模型在多个领域展现出了卓越的性能。在数学推理方面,它在AIME 2024竞赛中取得了86.7的高分,与OpenAI的o3-mini-high模型不相上下。在编程竞赛中,该模型在Codeforces平台上的通过率达到了55.0%,接近Gemini 2.5 Pro的水平。在科学推理任务上,Seed-Thinking-v1.5也取得了77.3%的优异成绩,同样接近业界领先模型。而在通用任务中,人类评估显示其表现超过了DeepSeek R1达8%,能够覆盖多种场景需求。
Seed-Thinking-v1.5模型采用了MoE架构,总参数达到200B,但激活参数仅为20B,这使其在保持高性能的同时,具备显著的推理成本优势。与DeepSeek R1相比,该模型的单位推理成本降低了50%,实现了性能与效率的完美平衡。
为了提升模型的表现力,豆包大模型团队在数据处理策略上进行了优化。针对可验证数据,如数学和代码题目,团队通过百万级数据的三重清洗流程,保留了10万道高难度题目,并设计了答案整数化改造和离线沙箱验证等机制,确保模型能够输出真实的推理过程。而对于非可验证数据,如创意写作,团队则基于豆包1.5 Pro训练集,剔除低价值样本,并采用两两对比奖励法,优化生成质量。
团队还构建了全新的评测基准,包括超难数学数据集BeyondAIME,该数据集包含100道无答案题干的题目,旨在解决现有测试区分度不足的问题。这一举措不仅提升了模型的评测准确性,也为后续的优化提供了有力支持。
在奖励模型方面,团队提出了双轨奖励机制,以兼顾“对错分明”与“见仁见智”的任务。对于可验证任务,团队开发了两代验证器,从字符匹配升级为推理步骤逐行对比,确保了模型输出的准确性。而对于非可验证任务,团队则引入pairwise对比训练,通过大量“AB测试”捕捉人类对创意、情感等的隐性偏好,从而避免了“众口难调”的问题。这一双轨奖励机制不仅提升了模型的训练效率,也使其在不同场景下都能表现出色。
在训练方法上,Seed-Thinking-v1.5采用了“监督精调+强化学习”的双阶段优化策略。在监督精调阶段,团队基于40万高质量实例构建了长思考链数据集,并结合人工与模型协同筛选,确保模型能够“像人类一样思考”。而在强化学习阶段,团队通过三重数据引擎、算法创新以及在线数据适配技术,解决了训练不稳定、长链推理断层等问题,使模型能够在动态调整数据分布的过程中保持最佳训练状态。
最后,为了应对20B MoE(总参数200B)的复杂训练需求,团队对底层架构进行了优化。HybridFlow编程模型支持算法快速探索与分布式并行运行,流式推理系统(SRS)则通过“流式推理”技术解耦模型演进与异步推理,将训练速度提升了3倍。三层并行架构结合张量/专家/序列并行,动态均衡负载,基于KARP算法优化GPU算力利用率,为模型的高效训练提供了有力保障。