近日,科技新闻界传来一则关于meta AI创新进展的报道。据报道,meta AI研发了一种名为Token-Shuffle的新方法,旨在解决自回归(AR)模型在生成高分辨率图像时所面临的挑战。
自回归模型是一种在时间序列分析中广泛应用的统计方法,它基于历史数据预测未来值。近年来,这种方法在语言生成领域取得了显著成就,并逐渐应用于图像合成。然而,在处理高分辨率图像时,AR模型遇到了瓶颈。与文本生成相比,图像合成需要处理数千个token,导致计算成本急剧增加,限制了AR模型在精细图像生成中的应用。
尽管扩散模型在高分辨率图像生成方面表现出色,但其复杂的采样过程和较慢的推理速度也成为其应用的局限。因此,meta AI推出的Token-Shuffle方法显得尤为重要。
Token-Shuffle的核心机制在于解决token效率问题。该方法通过识别多模态大语言模型(MLLMs)中视觉词汇的维度冗余,提出了一种创新策略:在Transformer处理前,将空间上相邻的视觉token沿通道维度合并,推理后再恢复原始空间结构。这种token融合机制不仅降低了计算成本,还保持了视觉质量,使自回归模型能够高效处理最高达2048×2048分辨率的图像。
具体来说,Token-Shuffle包括两个关键步骤:token-shuffle和token-unshuffle。在输入准备阶段,通过多层感知机(MLP)将空间相邻的token压缩为单个token,从而减少token数量。以窗口大小s为例,token数量可减少到原来的s²分之一,显著降低了Transformer的计算量。
Token-Shuffle还引入了针对自回归生成的classifier-free guidance(CFG)调度器,动态调整引导强度,优化文本-图像对齐效果。这一创新不仅提升了图像生成的质量,还为AR模型在高分辨率图像生成领域树立了新的标杆。
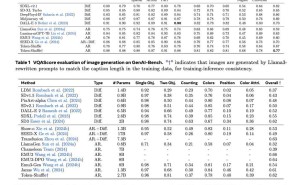
在实验中,Token-Shuffle展现了强大的实力。在GenAI-Bench基准测试中,基于2.7B参数的LLaMA模型,Token-Shuffle在“困难”提示下取得了VQAScore 0.77,超越了其他AR模型如LlamaGen和扩散模型LDM。同时,在Geneval基准测试中,Token-Shuffle的综合得分为0.62,为AR模型树立了新的标准。
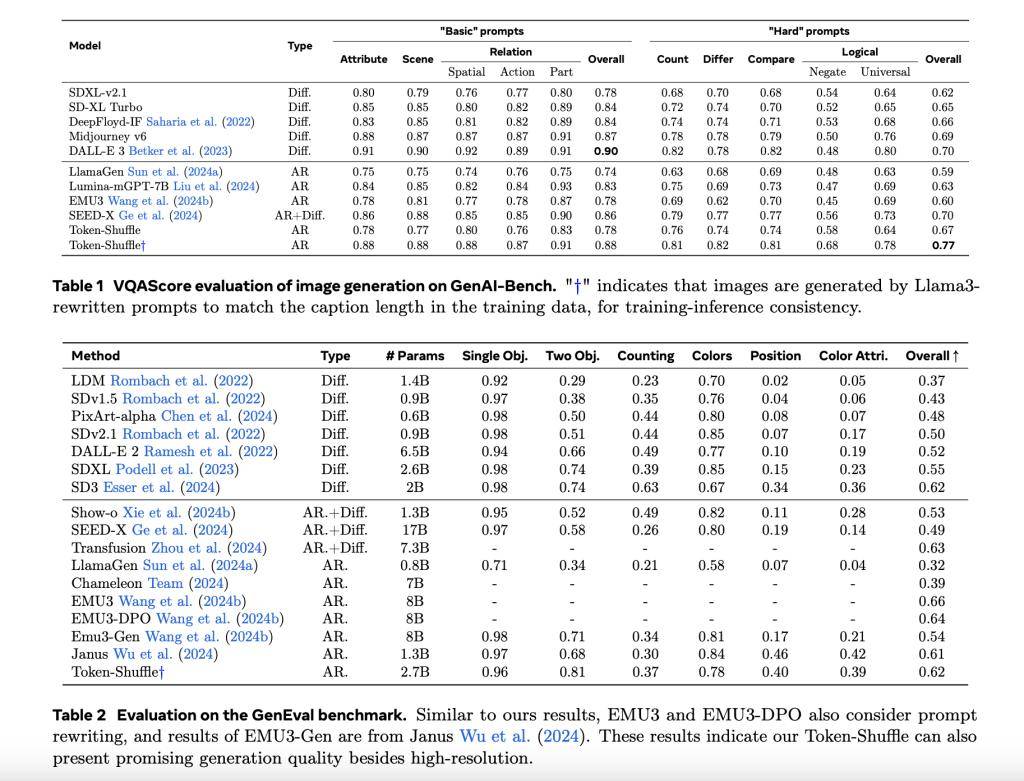
用户评估也显示,尽管在逻辑一致性方面略逊于扩散模型,但Token-Shuffle在文本对齐和图像质量上优于LlamaGen和Lumina-mGPT。这一成果不仅为图像合成领域带来了新的突破,也为未来AR模型在更高分辨率图像生成中的应用提供了可能。