近期,业界流传出一份据称是DeepSeek公司专家会议纪要的文件,内容涉及该公司的发布历程和未来优化方向。然而,DeepSeek官方迅速对此作出回应,明确否认了这份文件的真实性。
DeepSeek在声明中强调,公司从未授权任何员工参与券商投资者交流会,所谓的“DeepSeek专家”并非公司成员,所传递的信息亦不属实。公司内部有着严格的规章制度,明确禁止员工接受外部访谈或参与各类投资者信息交流会议。所有相关信息均以公司公开披露为准。
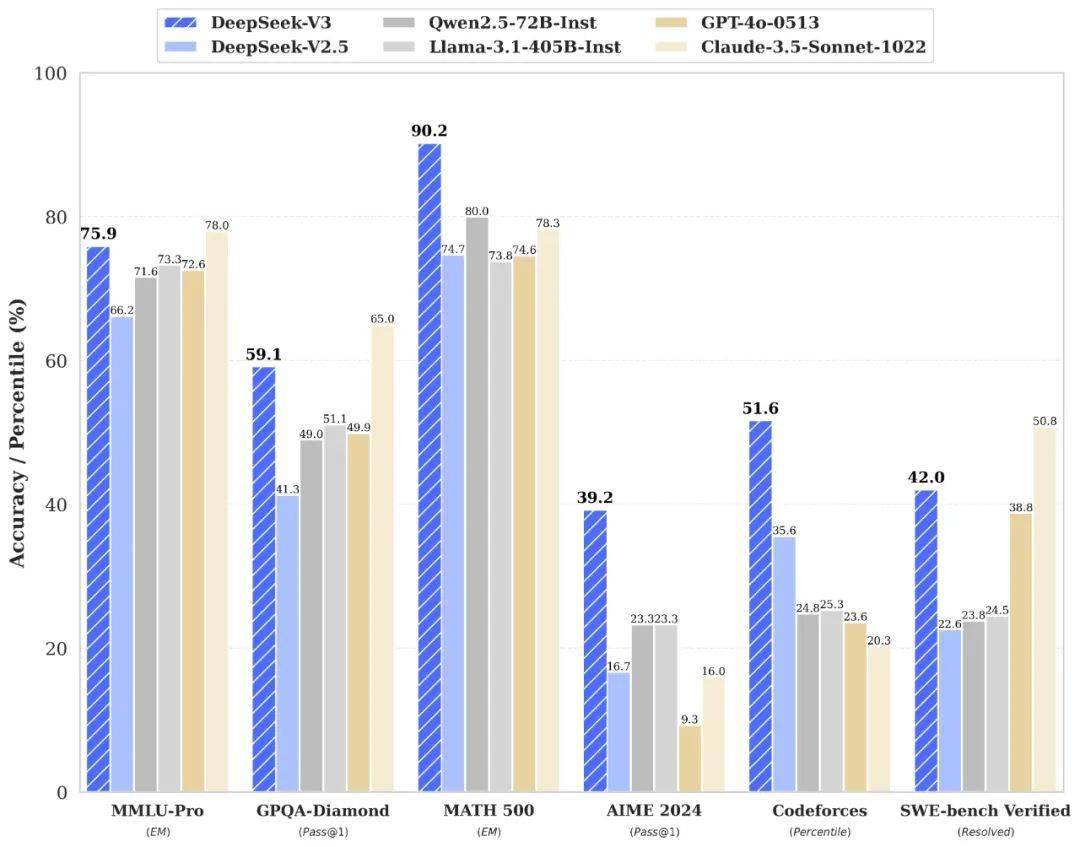
值得注意的是,DeepSeek在官方公众号“深度求索”上于12月26日发布了一篇博文,宣布正式上线并同步开源了DeepSeek-V3模型。用户现在可以通过访问官网chat.deepseek.com,与这一最新版V3模型进行对话。
DeepSeek-V3模型是一个拥有6710亿参数的专家混合(MoE)模型,其中激活参数达到370亿,该模型在14.8万亿token的数据上进行了预训练。据DeepSeek介绍,DeepSeek-V3在多项评测中的表现超越了Qwen2.5-72B和Llama-3.1-405B等开源模型,其性能甚至可以与世界顶尖的闭源模型如GPT-4o和Claude-3.5-Sonnet相媲美。
DeepSeek的这一最新进展,无疑在人工智能领域引起了广泛关注。随着DeepSeek-V3模型的开源,业界对其性能和应用前景的期待也进一步增加。











