OpenAI近日在人工智能技术领域迈出了重要一步,于3月20日正式宣布推出全新的语音转文本(speech-to-text)及文本转语音(text-to-speech)模型,旨在显著提升语音处理能力,并为开发者提供更加精确、高度可定制的语音交互系统解决方案。这一举措预示着人工智能语音技术商业化应用的进一步加速。
在语音转文本领域,OpenAI推出了gpt-4o-transcribe和gpt-4o-mini-transcribe两款模型,据官方宣称,这两款模型在单词错误率(WER)、语言识别精度以及整体准确性方面,均超越了其现有的Whisper系列模型。它们能够支持超过100种语言,通过强化学习和多样化高质量音频数据集的深入训练,成功捕捉语音中的细微特征,有效减少误识别情况,特别是在嘈杂环境、不同口音及语速变化下,展现出更加稳定的性能。
这两款新模型的问世,无疑为开发者提供了更为强大的工具,使他们能够构建出更加精准、适应性更强的语音交互系统,满足不同场景下的需求。无论是智能客服、智能家居,还是自动驾驶等领域,都将因此受益。
在文本转语音方面,OpenAI同样推出了创新的gpt-4o-mini-tts模型。这款模型允许开发者通过简单的指令,如“模拟耐心客服”或“生动故事叙述”,来控制语音的风格和语调。这一特性使得gpt-4o-mini-tts在客服领域具有巨大潜力,能够合成更具同理心的语音,从而显著提升用户体验。同时,它也为创意内容制作带来了无限可能,如有声书录制、游戏角色配音等。
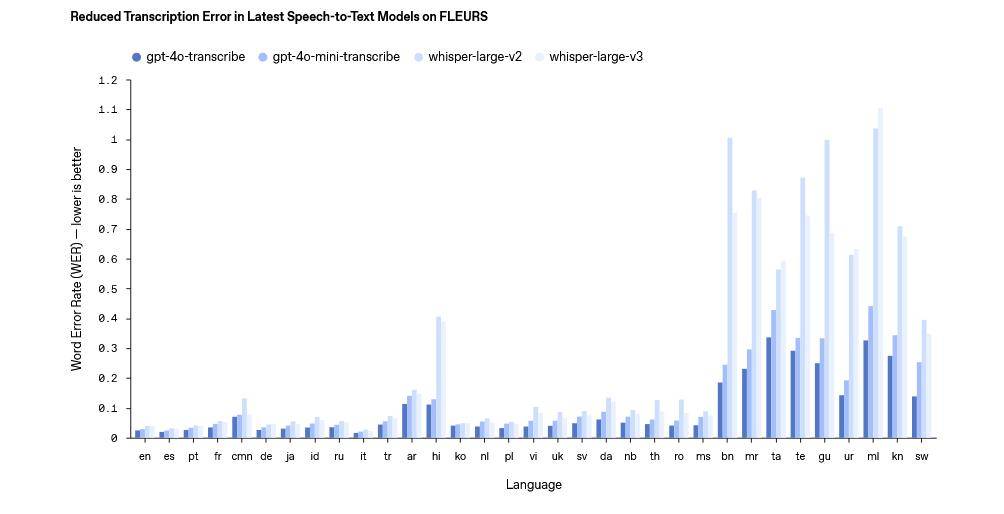
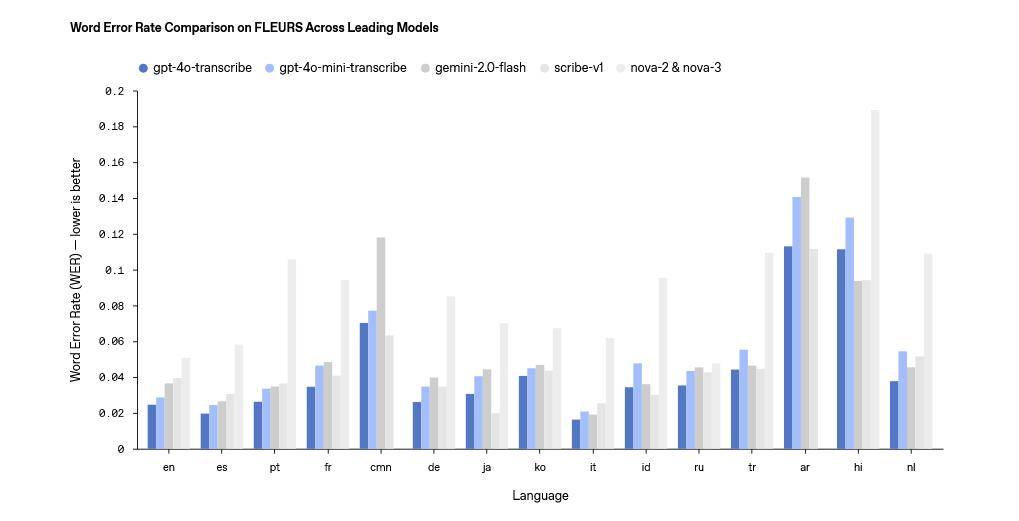
为了帮助开发者更好地了解和使用这些新模型,OpenAI还公布了详细的费用说明。gpt-4o-transcribe模型在处理音频输入时,每100万tokens的费用为6美元,文本输入和输出的费用分别为2.5美元和10美元,每分钟的成本为0.6美分。相比之下,gpt-4o-mini-transcribe模型的费用更加亲民,音频输入、文本输入和输出的费用分别为3美元、1.25美元和5美元,每分钟的成本仅为0.3美分。而gpt-4o-mini-tts模型则按输入和输出分别计费,每100万tokens的输入费用为0.6美元,输出费用为12美元,每分钟的成本为1.5美分。
OpenAI此次推出的新模型,不仅展示了其在人工智能技术领域的深厚积累和创新实力,也为整个行业树立了新的标杆。随着这些模型的不断优化和推广,人工智能语音技术将在更多领域发挥重要作用,推动社会进步和产业发展。