英伟达在NVIDIA GTC 2025大会上宣布,其最新推出的NVIDIA Blackwell DGX系统在DeepSeek-R1大模型推理性能上创造了世界纪录。这一突破性进展标志着英伟达在人工智能推理技术上的又一次飞跃。
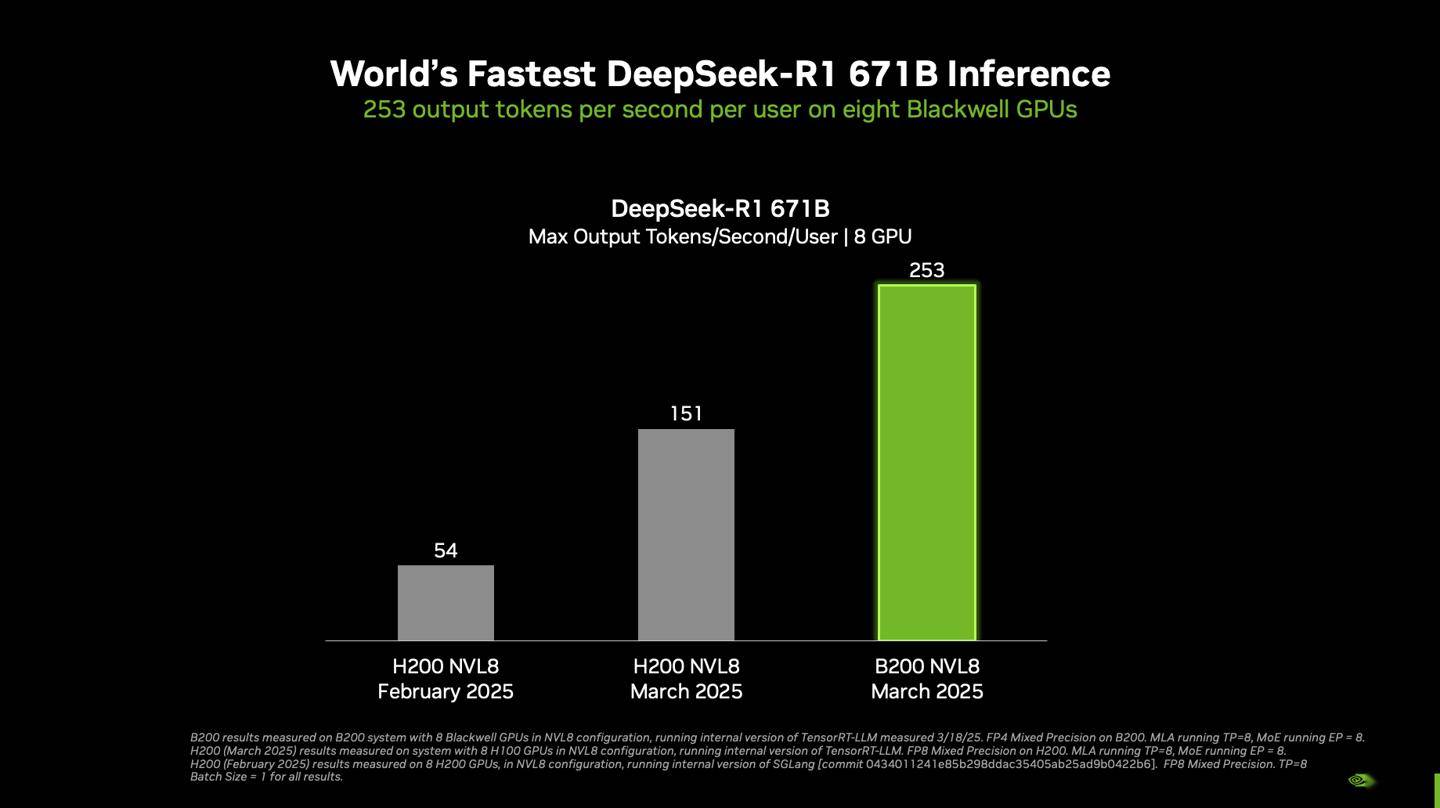
据悉,在单个搭载八块Blackwell GPU的DGX系统上,DeepSeek-R1模型以6710亿参数的满血状态运行,实现了每用户每秒超过250 token的响应速度,系统整体吞吐量更是突破了每秒3万token的大关。这一数据不仅彰显了Blackwell GPU的强大性能,也展示了英伟达在优化大型语言模型推理方面的深厚实力。

英伟达强调,随着Blackwell Ultra GPU和Blackwell GPU的不断升级,NVIDIA平台将继续在推理性能上实现新的突破。这一承诺不仅体现在硬件上,还体现在软件优化上。英伟达通过结合硬件和软件的力量,自2025年1月以来,成功将DeepSeek-R1 671B模型的吞吐量提高了约36倍。
在会上,英伟达还展示了不同配置下的DGX系统性能。包括DGX B200(8块GPU)和DGX H200(8块GPU)在内的单节点配置,在采用TensorRT-LLM软件的最新内部版本进行测试时,展现了出色的推理性能。测试参数包括输入1024 token和输出2048 token,并发性达到最大。在计算精度上,B200采用了FP4精度,而H200则采用了FP8精度。
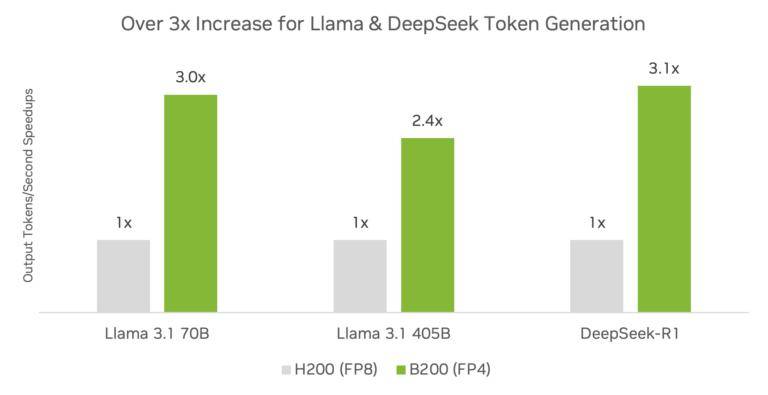
英伟达还对比了Blackwell架构与Hopper架构在推理性能上的差异。结果显示,Blackwell架构与TensorRT软件相结合,可以显著提升推理性能。在DeepSeek-R1、Llama 3.1 405B和Llama 3.3 70B等模型上,使用FP4精度的DGX B200平台和DGX H200平台相比,推理吞吐量提高了3倍以上。
英伟达还展示了不同数据集上DeepSeek-R1模型的精度表现。在FP4和FP8精度下,DeepSeek-R1模型在MMLUG、SM8K、AIME 2024、GPQA和DiamondMATH-500等数据集上的表现均十分出色。值得注意的是,在使用TensorRT Model Optimizer的FP4训练后量化(PTQ)技术时,DeepSeek-R1模型在不同数据集上的精度损失微乎其微,这进一步证明了英伟达在量化技术上的领先地位。
英伟达表示,在对模型进行量化以利用低精度计算优势时,确保精度损失最小化是生产部署的关键。通过不断的技术创新和优化,英伟达将继续为客户提供更高效、更准确的AI推理解决方案。